LogEval
大规模语言模型日志分析能力综合基准测试套件
关于LogEval
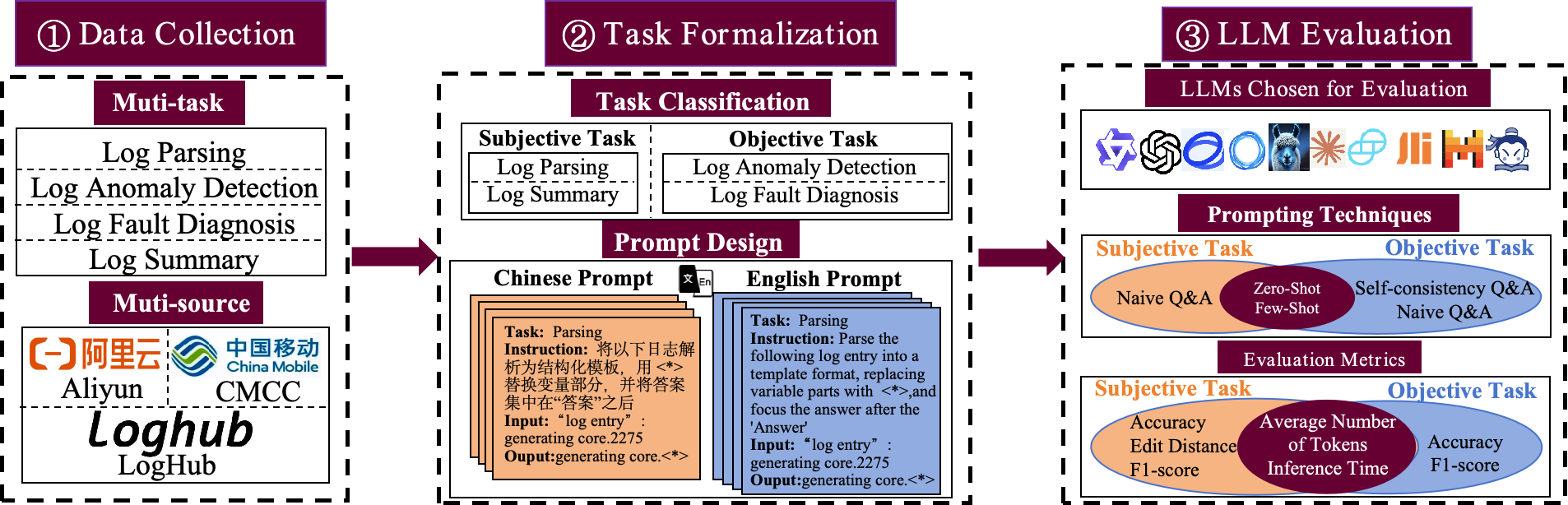
LogEval是一个全面的基准测试套件,用于评估大型语言模型在日志解析、异常检测、故障诊断和日志总结方面的能力。使用4000个公开的日志数据条目和每个任务15个不同的提示,对多个主流大型语言模型进行了严格的评估,展示了大型语言模型在自一致性和少次学习方面的表现,并讨论了模型量化、中英文问答评估和提示工程方面的发现。其评价结果揭示了大型语言模型在日志分析任务中的优势和局限性,为研究人员在日志分析任务中选择模型提供了有价值的参考。你可以查看论文了解更多细节。
引用
@misc{cui2024logevalcomprehensivebenchmarksuite,
title={LogEval: A Comprehensive Benchmark Suite for Large Language Models In Log Analysis},
author={Tianyu Cui and Shiyu Ma and Ziang Chen and Tong Xiao and Shimin Tao and Yilun Liu and Shenglin Zhang and Duoming Lin and Changchang Liu and Yuzhe Cai and Weibin Meng and Yongqian Sun and Dan Pei},
year={2024},
eprint={2407.01896},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.01896},
}
联系我们
对于LogEval有任何问题,或者有可能的合作意向,可以点击 结果提交 页面,填写您的邮箱,或者直接发送邮件到 cuitianyu@mail.nankai.edu.cn